
Overview
The evolution from data warehouse to data lakes to a Lakehouse architecture
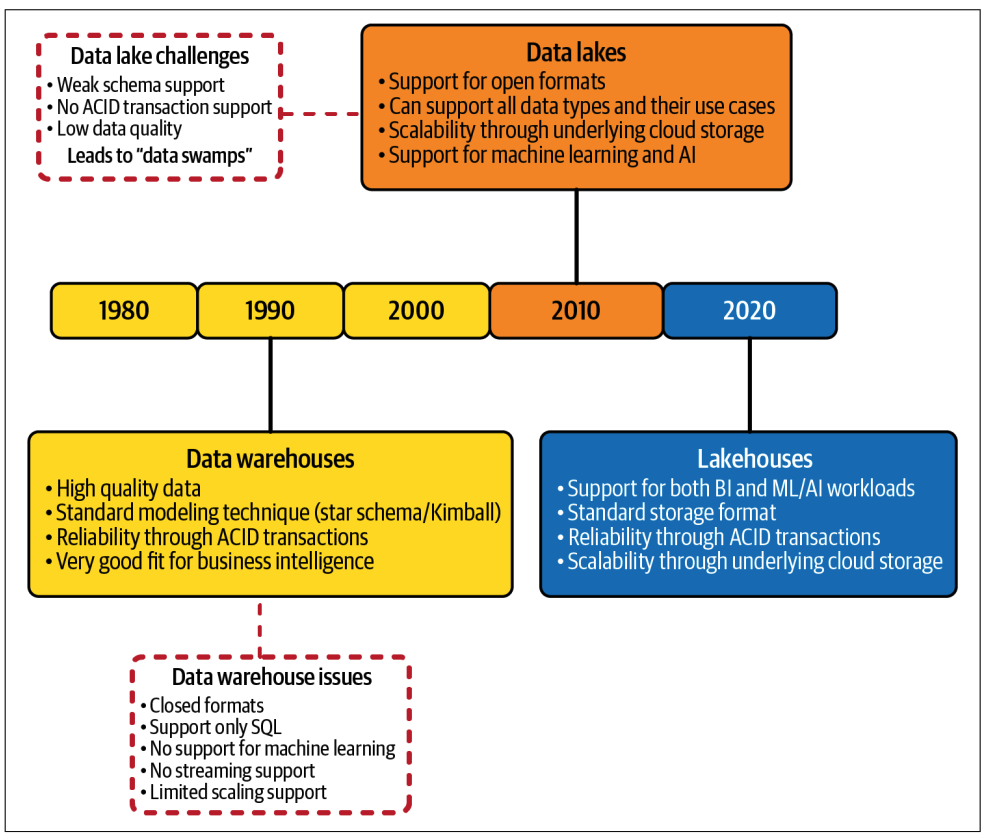
Data Warehouse Architecture (1990s)
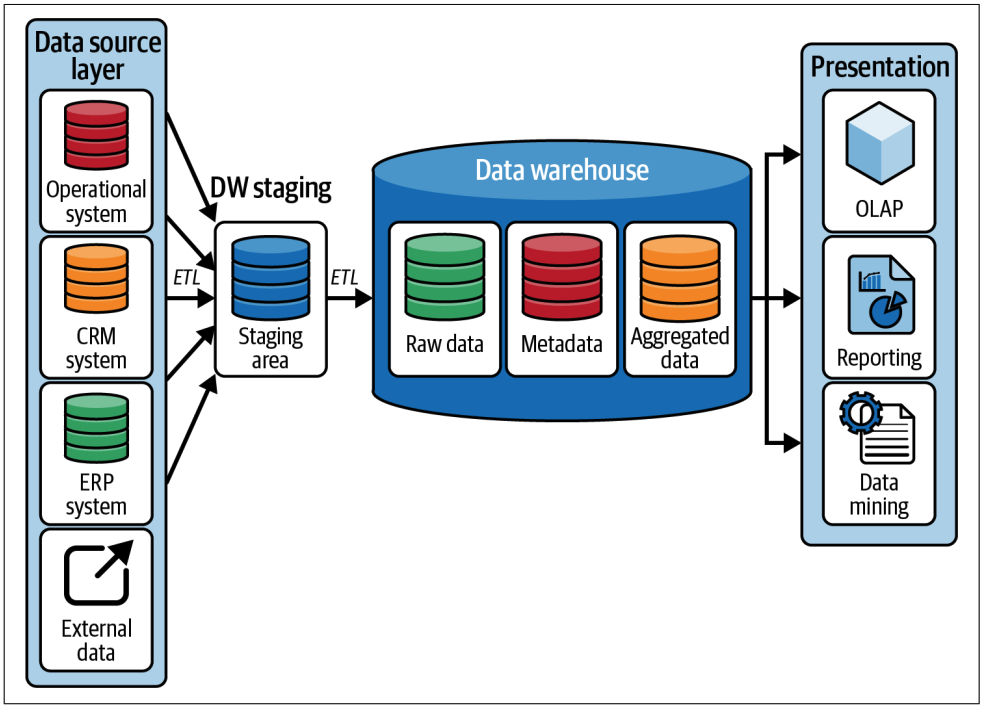
- Data warehouses are physically implemented on a monolithic physical architecture, made up of a single large node, combining memory, compute, and storage. This monolithic architecture forces organizations to scale their infrastructure vertically, resulting in expensive, often over-dimensioned infrastructure, which was provisioned for peak user load, while being near idle at other times.
- Data warehouse introduced the need for a comprehensive data model that spans the different subject areas in a corporate enterprise. The technique used to create these models became known as dimensional modeling.
- A dimensional model is described by a star schema
The fast rise of the internet and social media and the availability of multimedia devices such as smartphones disrupted the traditional data landscape, giving rise to the term big data. Big data is defined as data that arrives in ever higher volumes, with more velocity, in a greater variety of formats with higher veracity. These are known as the four Vs of data: volume, velocity, variety, and veracity.
Data Lakes Architecture (2015)
A data lake is a cost-effective central repository to store structured, semi-structured, or unstructured data at any scale, in the form of files and blobs. The term “data lake” came from the analogy of a real river or lake, holding the water, or in this case data, with several tributaries that are flowing the water (aka “data”) into the lake in real time.
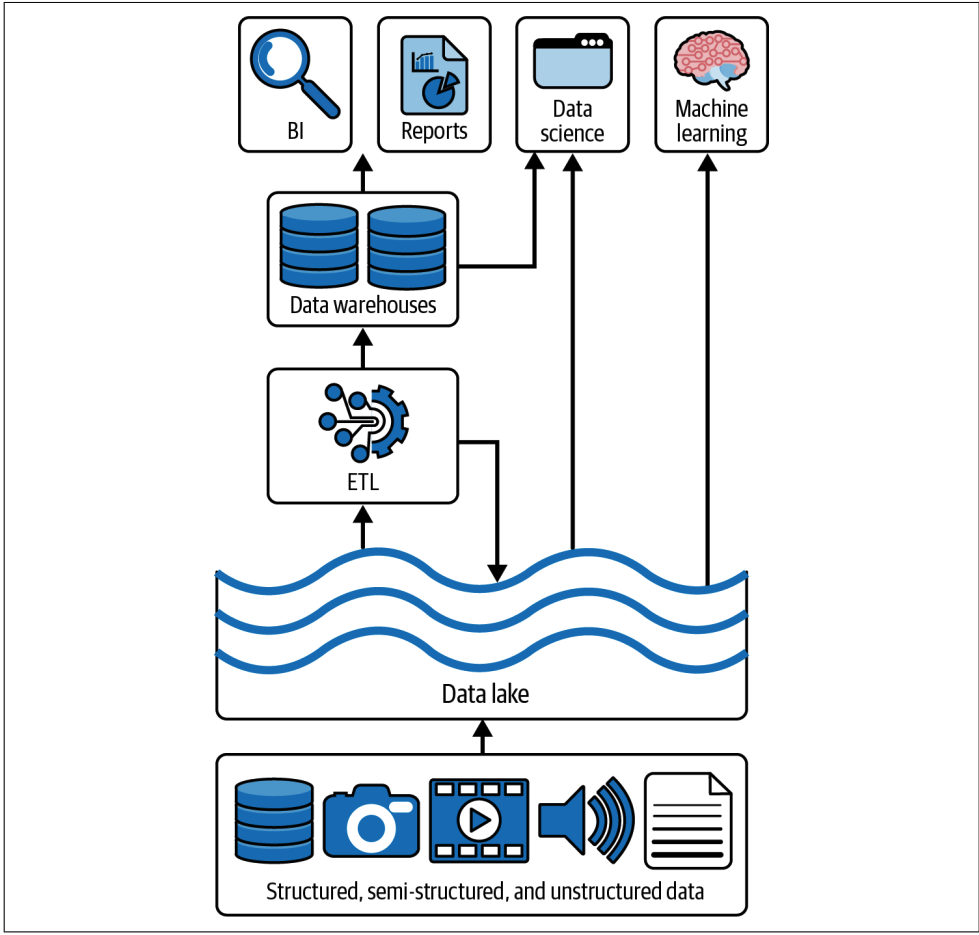
- The initial data lakes and big data solutions were built with on-premises clusters, based upon the Apache Hadoop open source set of frameworks (HDFS & MapReduce). Later, the cloud data lakes (S3, GCS) start replacing HDFS with superior SLAs, geo-replication and extremely low cost.
- At the lowest level, the unit of storage in a data lake is a blob of data. Blobs are by nature unstructured, enabling the storage of semi-structured and unstructured data, such as large audio and video files. At a higher level, the cloud storage systems provide file semantics and file-level security on top of the blob storage, enabling the storage of highly structured data. Because of their high bandwidth ingress and egress channels, data lakes also enable streaming use cases, such as the continuous ingestion of large volumes of IoT data or streaming media.
- Datalake is scalable, bring data into one place, with open data types. However, transforming the data into a form that deliver business can be expensive, lack of schema enforcement and no transactional guarantees.
Data Lakehouse Architecture (2020)
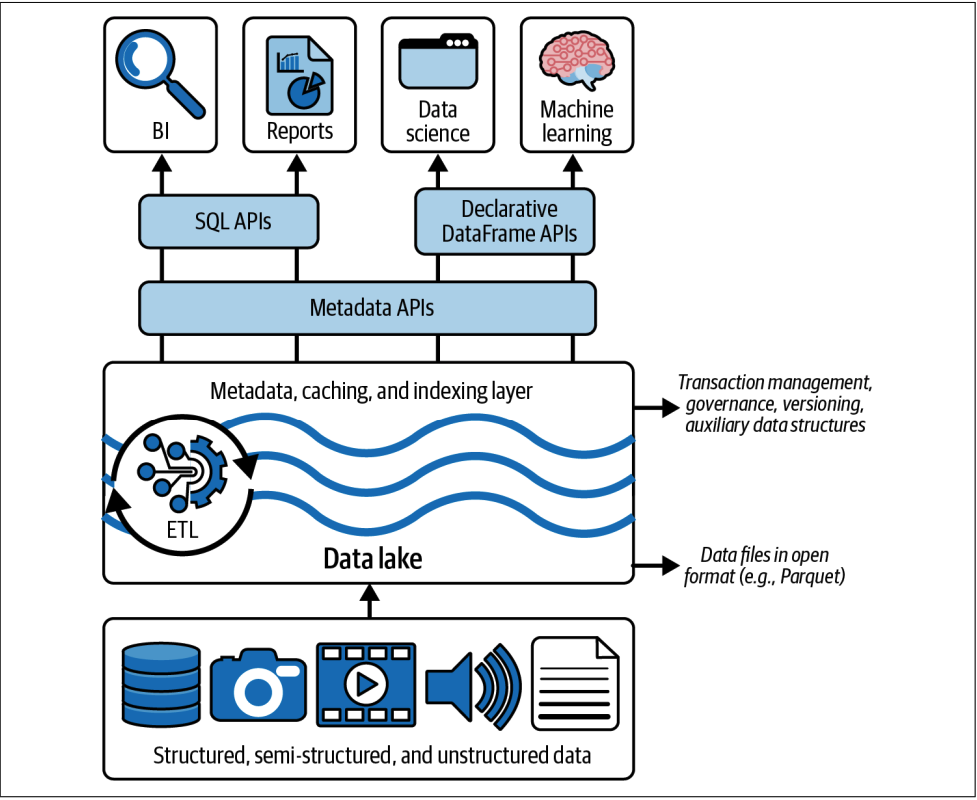
Lakehouse is a data management system based upon low-cost and directly accessible storage that also provides analytics DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching and query optimization
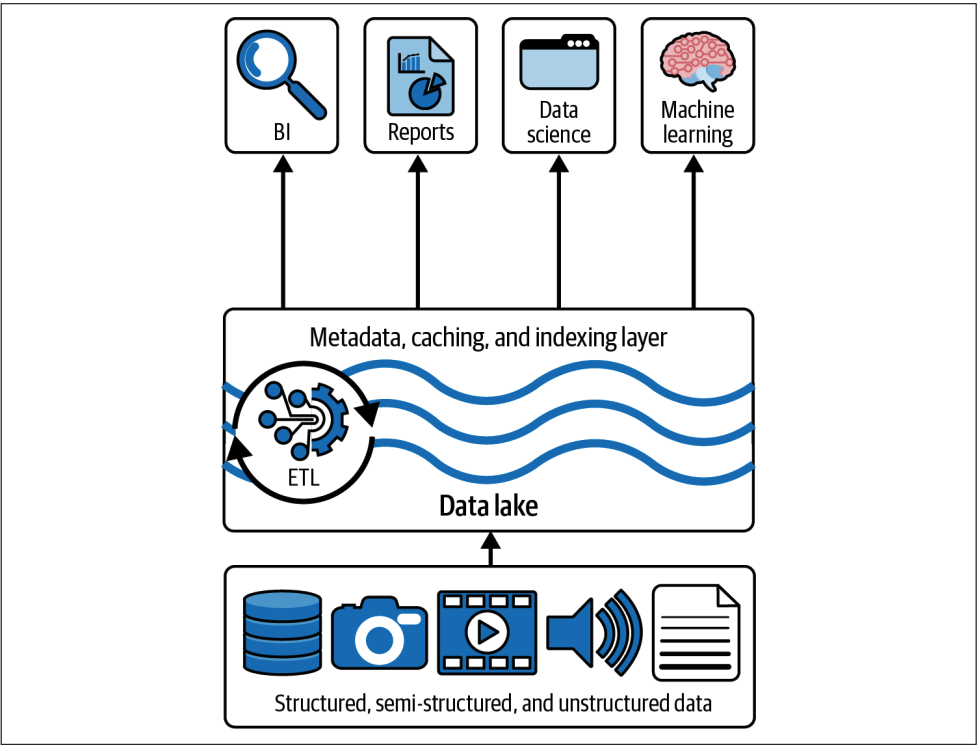
Lakehouses leverage low-cost object stores, like Amazon S3, ADLS, or GCS, storing the data in an open source table format, such as Apache Parquet. However, since lakehouse implementations run ACID transactions against this data, we need a transactional metadata layer on top of the cloud storage, defining which objects are part of the table version.
Delta Lake
Delta Lake is an open-table format that combines metadata, caching, and indexing with a data lake storage format. Delta lake is the transactional layer of the lake house architecture. This brings ACID guarantees to the lakehouse,.

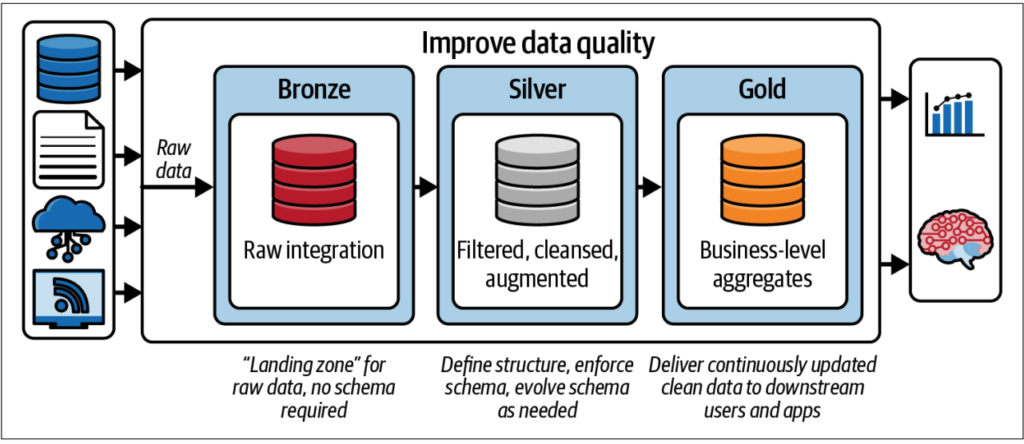
The Medallion Architecture
Reference
- Haelen, B., & Davis, D. (2023). Delta Lake: up and running: Modern Data Lakehouse Architectures with Delta Lake. O’Reilly Media.