
Data Lake is an open-source project that enables building a data lakehouse on the top of existing cloud storage.

| It is | It is not |
|---|---|
| Open sourced | Proprietary Technology |
| Builds upon standard data formats | Storage format |
| Optimized for cloud object storage | Storage medium |
| Built for scalable metadata handling | Database service or data warehouse |
Delta Lake uses versioned Parquet files to store data. Parquet is a column-oriented format. This helps to 1) support flexible compression and extendable encoding schemas for each data type (column). 2) Fast query from the specific columns. 3) boost query by providing column metadata (min/max etc.)
When outputs data using .format("delta") instead of .format("parquet") , _delta_log file is added compared to the traditional parquet outputs. It contains a transaction log with every single operation performed on your data. This is essential to build ACID transaction support, scalable metadata and time travel features.
ACID Transactions Support
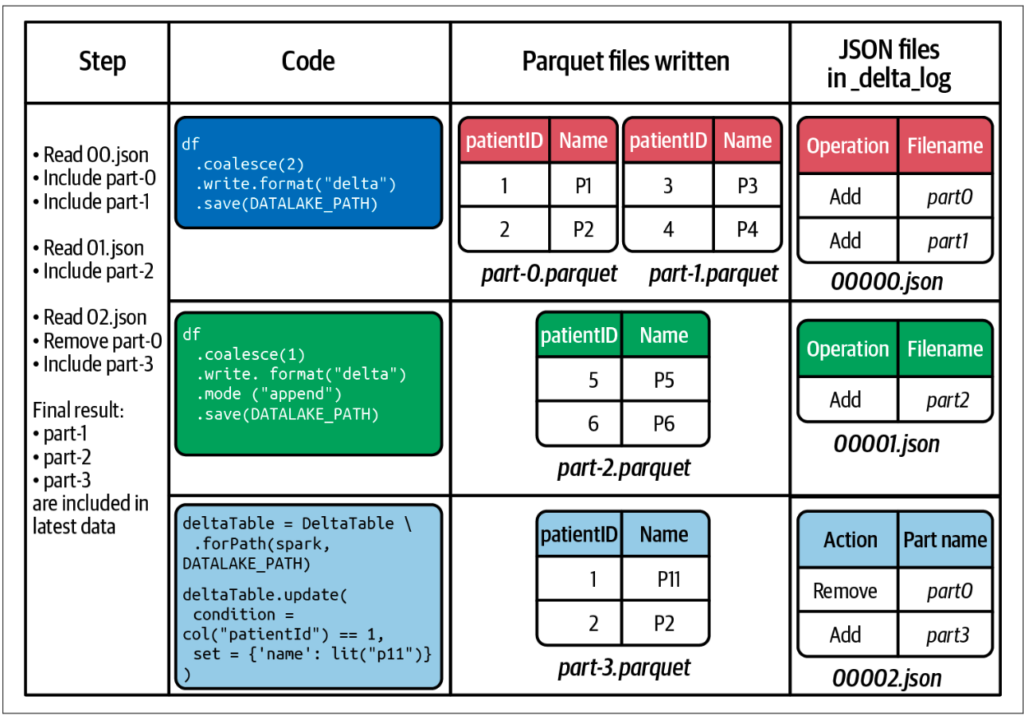
When the system is write new data, it first writes the data file and then update the __delta_log_ file. Each operation creates a 0..00X.json file inside the delta_log and it records the operation as well as the affected file.
Below is an example of the steps it takes to write and update the records. Note that the final read after changing the patient ID from P1 to P11 is to read out part-1,2,3.parquet instead of all files given the last json 00002.json indicates to skip reading part-0.parquet
Scaling Massive Metadata
Delta Lake writer will generate checkpoint file every 10 commits. The checkpoint file saves the state of the table at a given point in time and save the list in native Parquet format. This gives the Spark reader a shortcut to avoid reprocessing thousands of small JSON files leads to inefficiency.
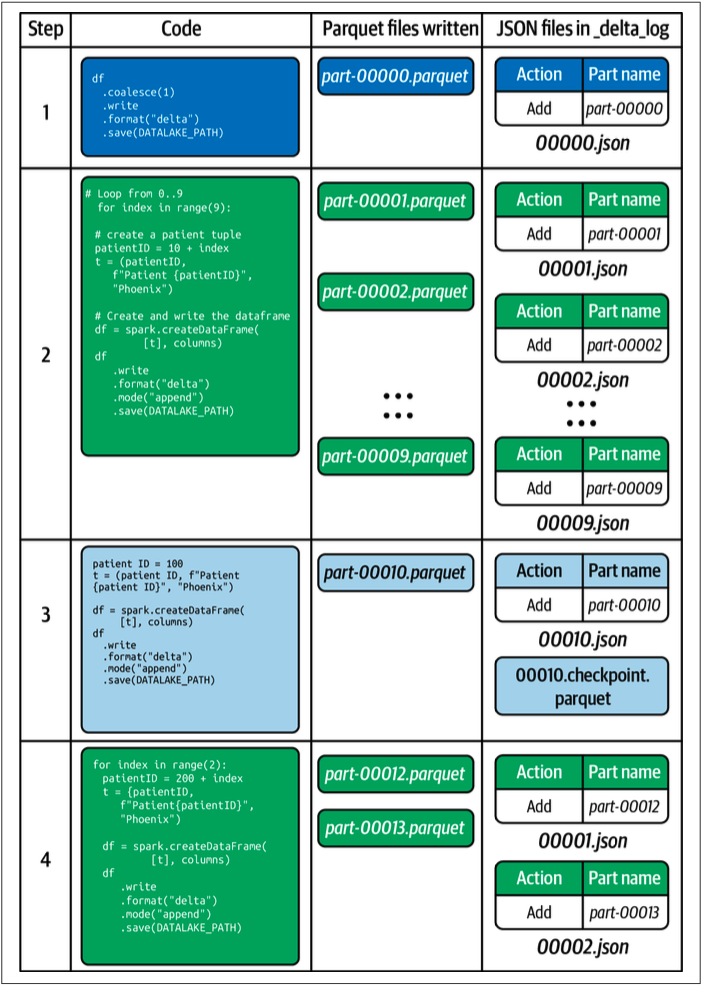
If Delta Lake needs to re-create the state of the table from above operations, it will simply read the checkpoint file (000010.checkpoint.parquet), and reapply the two additional log entries (00011.json and 00012.json).
In conclusion, Delta Lake's adept handling of ACID transactions and intelligent metadata scaling embodies a paradigm shift in data lakehouse architecture. Its capabilities lay the foundation for robust, efficient, and scalable data management.
Reference
- Haelen, B., & Davis, D. (2023). Delta Lake: up and running: Modern Data Lakehouse Architectures with Delta Lake. O’Reilly Media.