
In the realm of data management, the need to efficiently track and manage changes in datasets has led to the development of Change Data Capture (CDC) techniques. CDC involves the identification and monitoring of data alterations, or deltas, to enable streamlined actions using the modified data. This post delves into the significance of CDC, exploring why it is essential for minimizing data transfers and enhancing processing times, particularly in real-time or near-real-time integration scenarios. Within the broader CDC framework, Specific Data Capture (SDC) emerges as a set of techniques, with distinct types like SCD Type 1, SCD Type 2, and SCD Type 3, each catering to different requirements.
Moreover, the post highlights the integration of CDC into the Databricks platform through the application of SDC syntax on Delta Live Tables. The discussion covers the syntax's implementation in SQL and Python, demonstrating how it simplifies the process of change data capture, deduplication, and historical tracking in streaming tables. Additionally, the limitations of the APPLY CHANGES INTO query or apply_changes function are explored, emphasizing the necessity of configuring streaming tables as materialized views with append-only sources.
What is CDC?
CDC is a set of design patterns to determine and track the data that has changed (deltas) so the action can be taken using the changed data.
Why we need CDC?
CDC helps to minimize the data needs to get transferred and improve processing time when dealing with real-time or near-real-time integration. It helps to avoid full refresh when the system just needs to apply changes/updates to the original dataset
What is SDC?
SDC is a specific techniques that achieves CDC.
Types of SDC
- SCD Type 1: Overwriting Existing Data (The existing data is directly updated with new values)
- SCD Type 2: Preserving Historical Versions (Creating a new record to preserve the history of changes.)
- SCD Type 3: Limited Historical Versions (Adding extra columns to store previous values)
Databricks SDC Syntax on Delta Live Tables
Databricks simplifies change data capture with the APPLY CHANGES API in Delta Live Tables. This syntax helps to deduplicates the records from the source streaming tables.
CREATE OR REFRESH STREAMING TABLE table_name;
APPLY CHANGES INTO LIVE.table_name
FROM source
KEYS (keys)
[IGNORE NULL UPDATES]
[APPLY AS DELETE WHEN condition]
[APPLY AS TRUNCATE WHEN condition]
SEQUENCE BY orderByColumn
[COLUMNS {columnList | * EXCEPT (exceptColumnList)}]
[STORED AS {SCD TYPE 1 | SCD TYPE 2}]
[TRACK HISTORY ON {columnList | * EXCEPT (exceptColumnList)}]apply_changes(
target = "<target-table>",
source = "<data-source>",
keys = ["key1", "key2", "keyN"],
sequence_by = "<sequence-column>",
ignore_null_updates = False,
apply_as_deletes = None,
apply_as_truncates = None,
column_list = None,
except_column_list = None,
stored_as_scd_type = <type>,
track_history_column_list = None,
track_history_except_column_list = None
)CDC Under the Hood
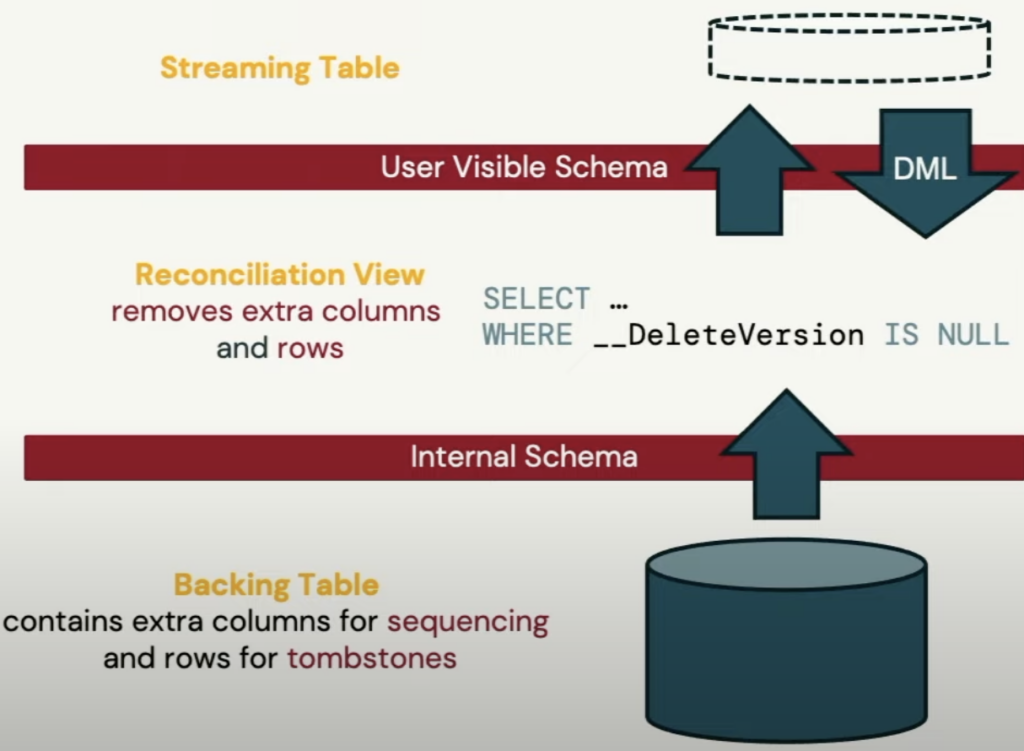
Databricks creates the backing table in Unity Catalog that has extra information for sequencing and tombstones rows. Then on top of the backing table, it has the Reconciliation View which reads the backing table and filter out unnecessaries rows that has been deleted or outdated so the streaming table can always see the most up-to-date data.
Limitations
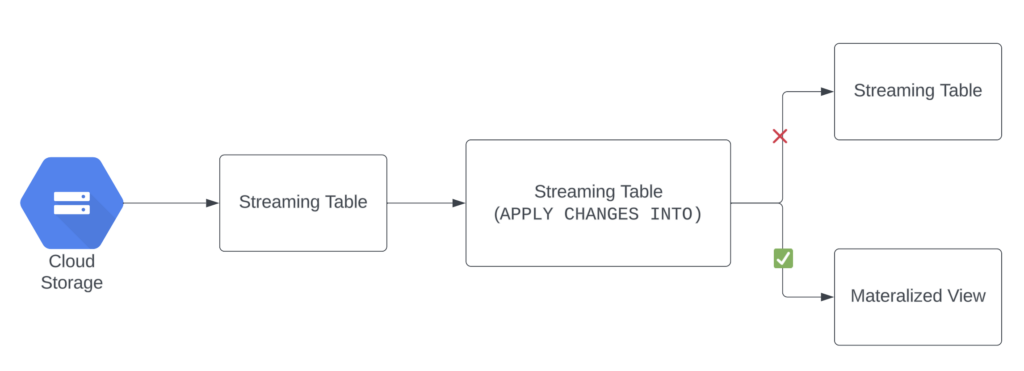
The target of the APPLY CHANGES INTO query or apply_changes function cannot be used as a source for a streaming table. A table that reads from the target of an APPLY CHANGES INTO query or apply_changes function must be a materialized view. This is because the streaming table must be configured with append-only sources.
Summary
As organizations strive for more agile and responsive data management, the adoption of CDC techniques, especially within powerful platforms like Databricks, becomes increasingly vital.
Reference
https://en.wikipedia.org/wiki/Change_data_capture
https://docs.databricks.com/en/delta-live-tables/cdc.html
https://www.youtube.com/watch?v=PIFL7W3DmaY&t=4249s